
Disclaimer: This video is not JUST for slide guitar, though I use a slide throughout. You can play the patterns without a slide and get just as much out of it. Don't let that scare you away if you …

Single String Approach To Understanding Music Theory On Guitar.
Music theory can be difficult to understand when you approach it from a "whole guitar" approach. I like to look at new scales, arpeggios etc. on a single string first. This helps me to wrap my …
Continue Reading about Single String Approach To Understanding Music Theory On Guitar. →

Intervals Of The Major Scale
With this video I'm beginning a series where I'm aiming to provide you with a solid foundation in what I call applied music theory, or functional music theory. Through this series we'll be exploring …

The Most Important Patterns For Understanding The Guitar Neck
Triads are a simple chord type that provide the key to decoding and unlocking the fretboard of the guitar. By using 3 big triad shapes, I show you how to navigate the entire neck in any key. Once you …
Continue Reading about The Most Important Patterns For Understanding The Guitar Neck →

Understanding Modes from the Tonal & Chromatic Perspectives
The concept of modes can seem challenging, but when you thoroughly understand it you are free to explore all the different possible sounds that scales can make. By visualizing the notes of a scale …
Continue Reading about Understanding Modes from the Tonal & Chromatic Perspectives →
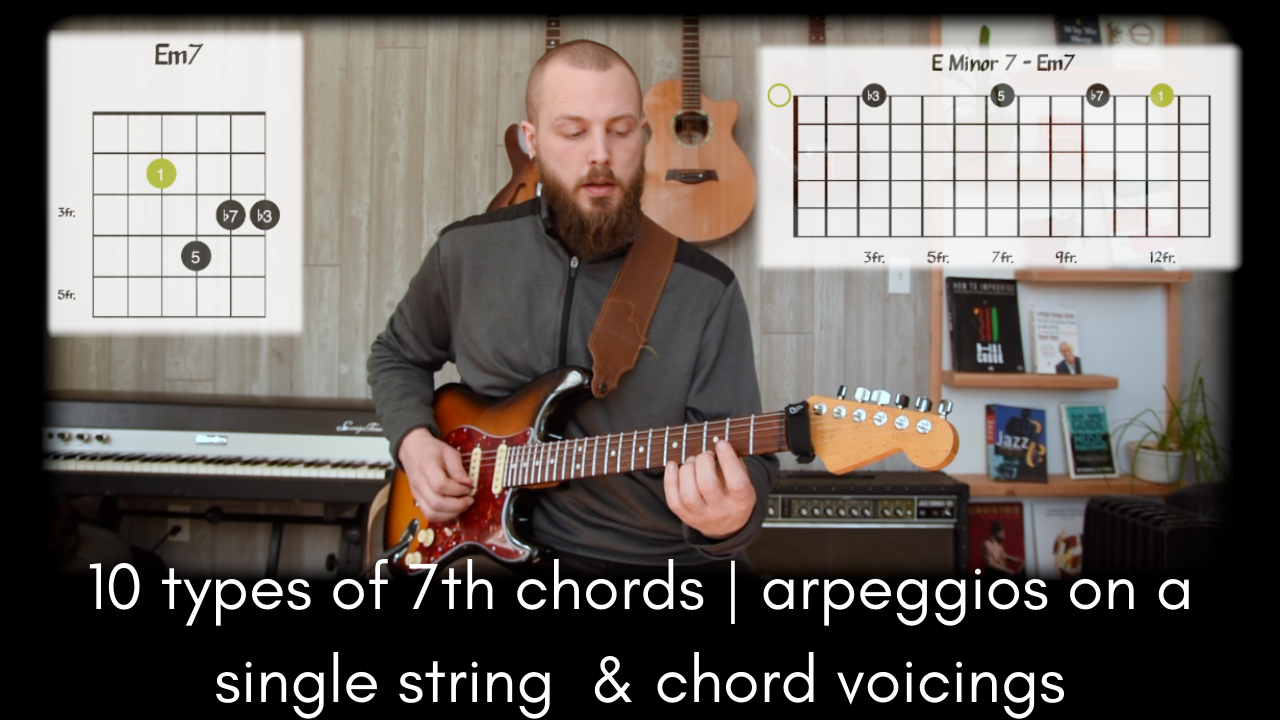
Music Theory | 10 Types of 7th Chords
Here is a quick tour of 10 different types of 7th chords. I demonstrate them using single string arpeggios, because I find that it is easier to understand the intervals that make up different chords …
Continue Reading about Music Theory | 10 Types of 7th Chords →